thesis
These are audio samples for Václav Volhejn’s Master thesis, Accelerating Neural Audio Synthesis. They showcase models that synthesize audio conditioned on pitch and loudness information. Given an input audio, we first extract its pitch (melody) and loudness. Then, given only these signals, the model tries to re-create the original sound. By training the model on a dataset of violin performances, it learns to create violin sounds.
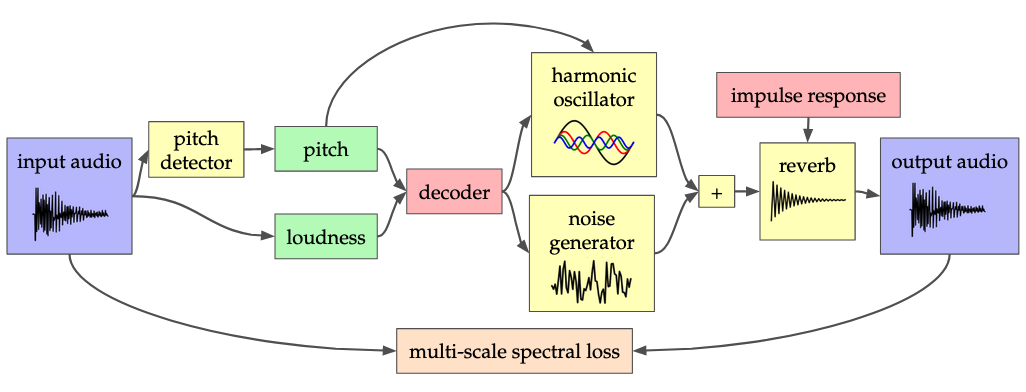
What is exciting about this is that if we have a violin model, we can use it to turn any sound into a violin (listen to the samples in “Violin timbre transfer” below). Whatever sound we give the model—voice, trumpet, guitar—the model only cares about the pitch and loudness signals. It then reconstructs the sound as if it were a violin.
The audio samples presented below were used in a subjective listening survey. The meaning of the rows is:
- Reference is the original audio file.
- DDSP-full is a baseline model from Engel et al.. About 6M parameters.
- DDSP-CNN is our speed-optimized model (see thesis). About 300k parameters.
- DDSP-CNN-Tiny is a smaller speed-optimized model: it has less than 2500 parameters!
- DDSP-CNN-Q is a version of DDSP-CNN quantized using static quantization.
- DDSP-CNN-Tiny-Q is a version of DDSP-CNN-Tiny quantized using static quantization.
Violin timbre transfer
These models were trained on the same data as the original DDSP models, namely four violin pieces by John Gartner that are accessible from the MusOpen royalty free music library.
The reference samples used are from various datasets: URMP, GuitarSet, Good-Sounds, SVNote and VocalSet .
| Guitar | Clarinet | Flute | Voice (m) | |
|---|---|---|---|---|
| Reference | ||||
| DDSP-full | ||||
| DDSP-CNN | ||||
| DDSP-CNN-Tiny | ||||
| DDSP-CNN-Q | ||||
| DDSP-CNN-Tiny-Q |
| Saxophone | Guitar | Voice (f) | |
|---|---|---|---|
| Reference | |||
| DDSP-full | |||
| DDSP-CNN | |||
| DDSP-CNN-Tiny | |||
| DDSP-CNN-Q | |||
| DDSP-CNN-Tiny-Q |
Violin
These are the violin models from above, but this time they are used to reconstruct the original data.
| 1 | 2 | 3 | |
|---|---|---|---|
| Reference | |||
| DDSP-full | |||
| DDSP-CNN | |||
| DDSP-CNN-Tiny | |||
| DDSP-CNN-Q | |||
| DDSP-CNN-Tiny-Q |
Trumpet
These models were trained on trumpet performances from the URMP dataset.
| 1 | 2 | 3 | |
|---|---|---|---|
| Reference | |||
| DDSP-full | |||
| DDSP-CNN | |||
| DDSP-CNN-Tiny | |||
| DDSP-CNN-Q | |||
| DDSP-CNN-Tiny-Q |